Growing BTC with @BenqiFinance leverage via @YouTube
HODLn $BTC is great! But what if you want to grow the amount of $BTC you have, along with its market value?
This video explores growing $BTC amount using leverage (borrowed $BTC) on @BenqiFinance.





Growing BTC with @BenqiFinance leverage via @YouTube
HODLn $BTC is great! But what if you want to grow the amount of $BTC you have, along with its market value?
This video explores growing $BTC amount using leverage (borrowed $BTC) on @BenqiFinance.
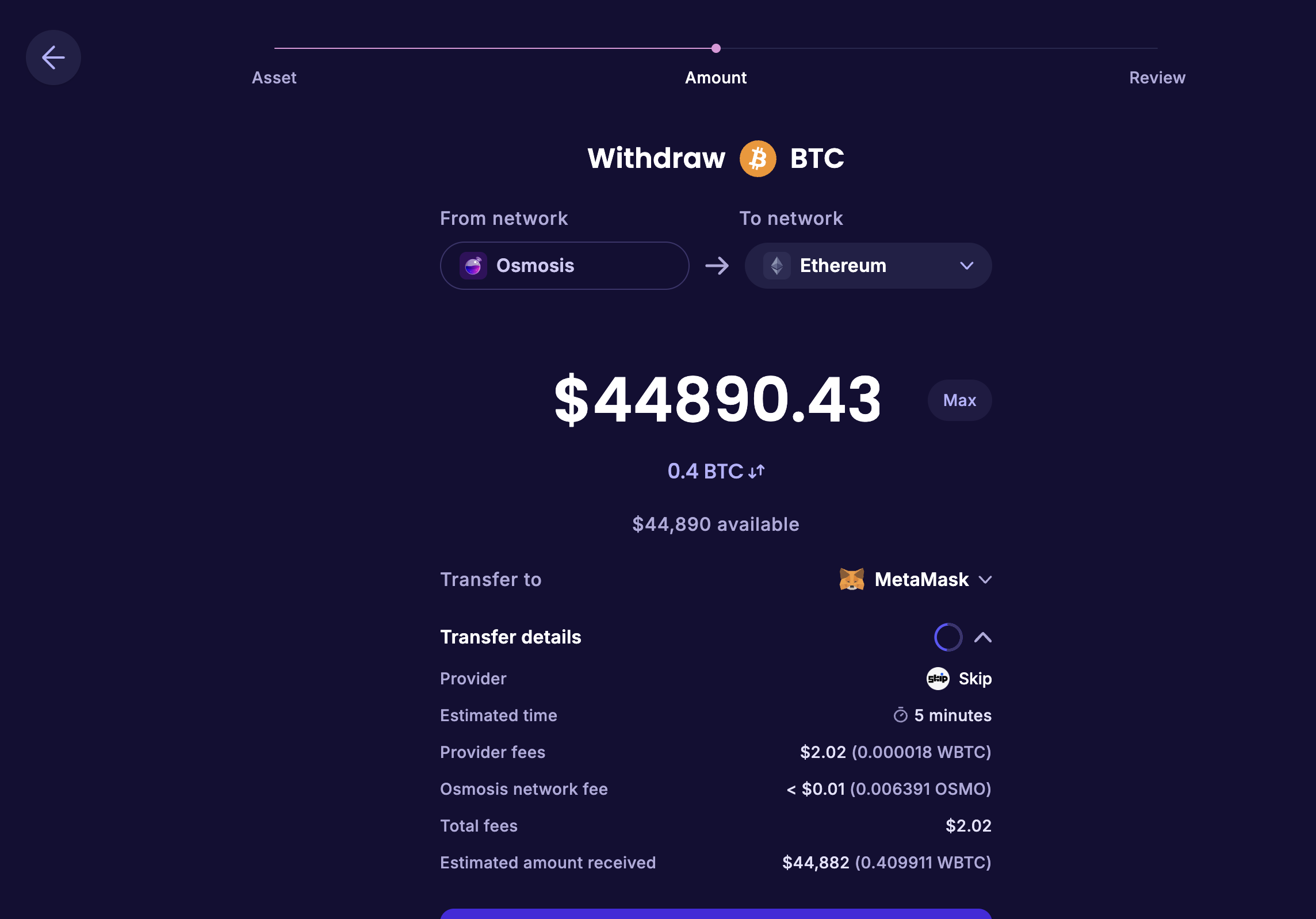
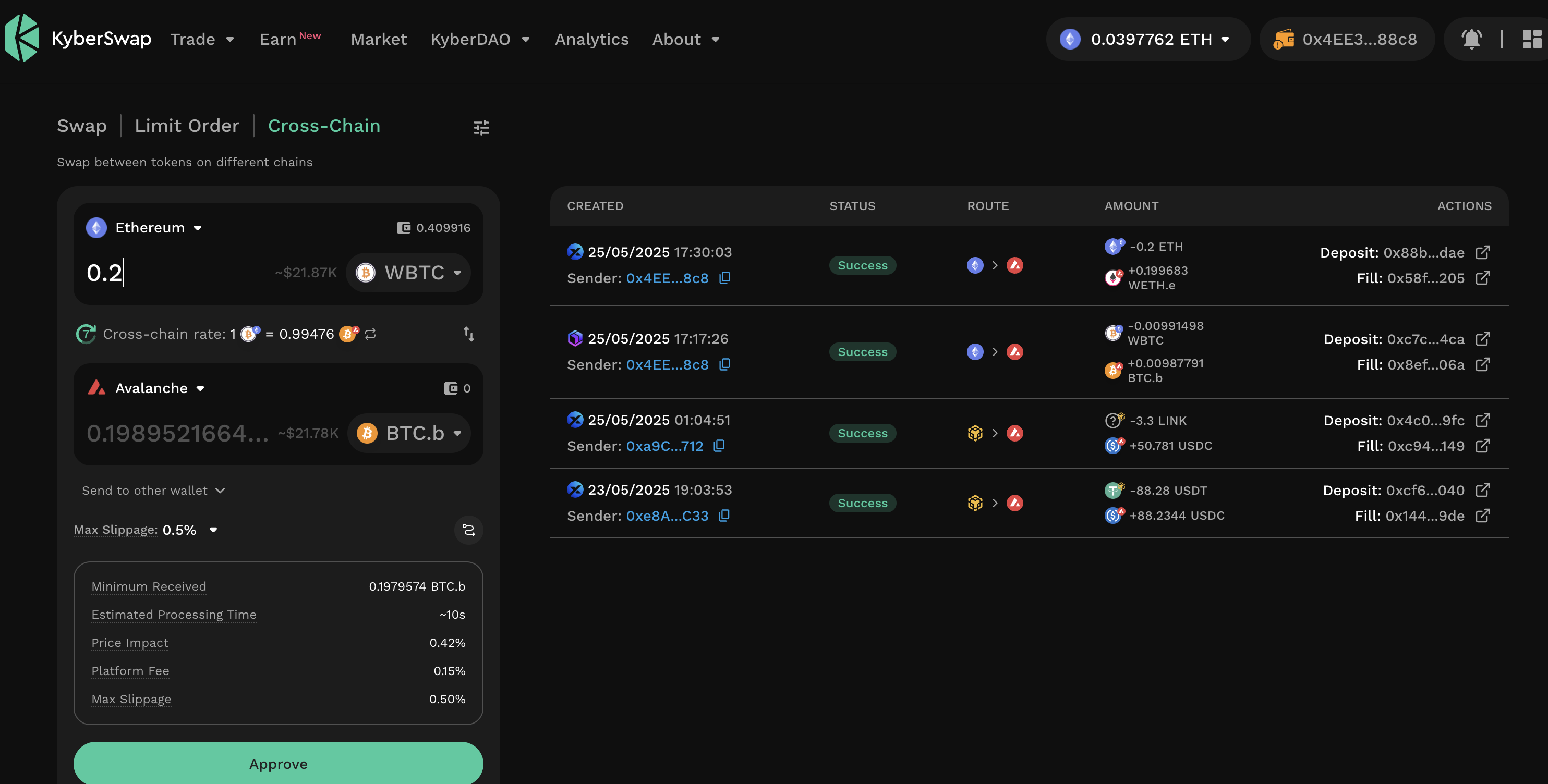
HOWTO withdraw crypto to the "Real World"™️




Monthly Cryptocurrency Income/Losses Report, February, 2025




Year (to date) profits/losses: $2,025.49
geophf, do you record every transaction by hand?
me: "What do you think?" 😤🙄







January, 2025 Blockaverse transaction report




transactions: 87
profits: $1,873.352
losses: -$554.17
fees: $29.41
total: $1,289.772




